
WPS office官网下载的地址的方法
模型对比
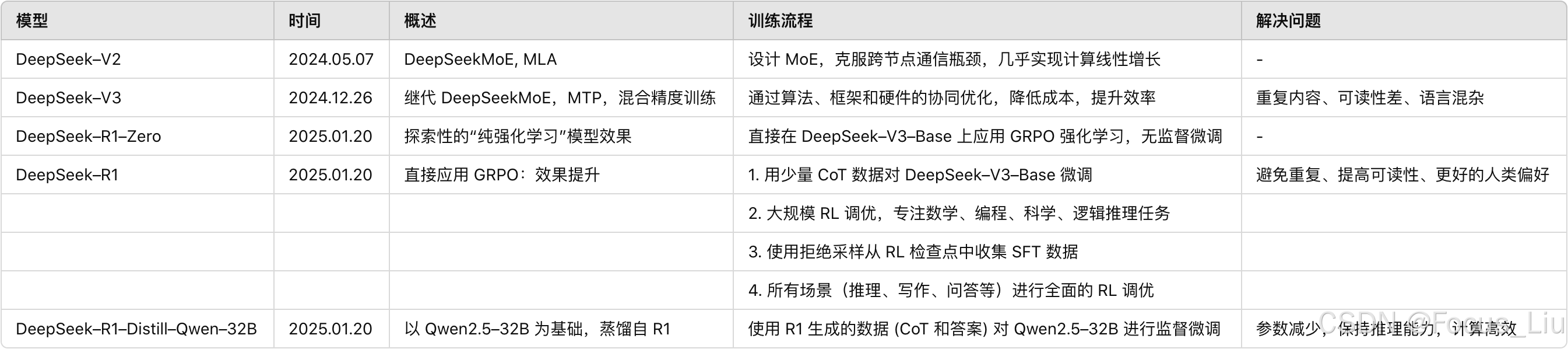
zero训练流程
直接在v3-base上进行强化学习,但是会出现,重复和可读性差、语言混合的问题。(由于目标策略π与base模型的策略π相差甚远,直接强化学习,奖励没有办法落到优化点,例如作文95分,你不知道5分是哪里扣的)
R1训练流程
使用少量CoT数据对v3-base进行微调(使其回复更好被人理解)大规模的强化学习(专注提升推理、编程、逻辑)再进行STF(拒绝采样从checkpoint中收集推理数据和非推理数据,进行SFT)强化学习(对齐人类偏好,知识无害性和有用性)
官网最新版的wps下载的地方是什么-V3:MoE架构,(MLA技术、无辅助损失的负载平衡策略、将 R1 的验证和反射模式融入 最新的官网wps下载地方-V3,并显著提高了其推理性能)。通过算法、框架和硬件的协同设计,我们克服了跨节点 MoE 训练中的通信瓶颈,几乎实现了完全计算-通信重叠。(大大降低训练成本,仅需2.788M H800 GPU 小时即可完成完整训练)
官网最新版的wps下载的地方是什么 V3模型发布(用更低的训练成本,训练出更好的效果)671B参数,激活37B。
最新的官网wps下载地方-R1-Zero:基于v3做强化学习得到。但是仍在重复、可读性差的问题。
官网最新版的wps下载的地方是什么-R1:MoE 架构,通过动态路由提升复杂任务性能。
最新的官网wps下载地方-R1-Distill-Qwen-32B:官网最新版的wps下载的地方是什么-R1蒸馏出的Dense模型。Student是Qwen。
《最新的官网wps下载地方-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model》
Multi-Head Latent Attention (MLA):通过对 Key 和 Value 进行低秩压缩,极大地减少了推理时的 KV cache,提高了推理效率,同时性能又比 MHA 更好。官网最新版的wps下载的地方是什么MoE:通过精细化的专家划分和共享专家的隔离,最新的官网wps下载地方MoE 能够在更低成本下训练更强大的模型。Device-Limited Routing: 在训练过程中对 MoE 架构进行了改进,实现了训练效率的提升,并在跨节点通信时加入了平衡负载策略。低成本训练:V2 在性能超越 官网最新版的wps下载的地方是什么 67B 的同时,训练成本却降低了 42.5%。论文地址:[2405.04434] 最新的官网wps下载地方-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
《官网最新版的wps下载的地方是什么 V3 Technical Report》
辅助损失函数 (Auxiliary Loss) 新策略: 解决了在 MOE 模型训练中,为了平衡负载而引入的辅助损失带来的模型性能损失问题。Multi-Token Prediction: V3 不再采用传统的单 Token 预测,而是采用多个 token 同时预测,从而提高了模型的整体性能,同时也有利于在推理阶段使用 speculative decoding 来提升推理速度。FP8 混合精度训练:使用 FP8 混合精度框架训练,并在大规模模型上验证了其可行性和有效性。通过 FP8 计算和存储,训练得到了显著的加速,并减少了 GPU 内存的使用。DualPipe:通过 DualPipe 算法,显著减少了 pipeline 过程中存在的 bubble,并使得通信过程和计算过程能够高度重叠,大幅提升了训练效率。高效的跨节点通信: 使用高效的跨节点 all-to-all 通信内核,充分利用 IB 和 NVLink 的带宽,减少训练时的通信开销。
最新的官网wps下载地方-V3/官网最新版的wps下载的地方是什么_V3.pdf at main · 最新的官网wps下载地方-ai/官网最新版的wps下载的地方是什么-V3 · GitHub
《官网最新版的wps下载的地方是什么 R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning》:
不依赖监督微调的 RL:最新的官网wps下载地方-R1-Zero 直接在 base 模型上运用 RL (强化学习)训练,证明AI大模型可以通过 RL 训练出更强的推理能力,不需要预先经过监督微调的训练。
多阶段强化学习:为了克服 RL 产生的不稳定性,官网最新版的wps下载的地方是什么-R1 先使用少量数据进行监督学习,再进行面向推理的强化学习。再通过拒绝采样的方式来做监督微调,并结合全场景的 RL,最终形成了 最新的官网wps下载地方-R1 模型。
小模型蒸馏:官网最新版的wps下载的地方是什么 团队探索了如何把 R1 模型的推理能力迁移到小模型中。他们使用蒸馏的方法训练了基于 Qwen 和 Llama 的系列小模型。
《最新的官网wps下载地方Math: Pushing the Limits of Mathematical Reasoning in Open Language Models》
GRPO:通过舍弃批评模型,转而使用群体分数来估计基线,显著减少了训练资源的使用,同时提升了数学推理能力。
LLM模型架构
当前主流的大模型(LLMs)都是decoder架构的模型。
Encoder架构是指:Attention可以看到输入序列的所有位置。如BERTDecoder架构是指:Attention只能看到当前词之前的位置。如GPT、LLaMA、官网最新版的wps下载的地方是什么等。
MoE和Dense架构区别
MoE架构推理、训练速度快,但是由于MoE架构一般比Dense参数量大,所以一般Dense更费内存。
Sinusoidal
介绍:原始Attention论文所使用的位置信息,能体现相对位置信息的绝对位置编码。
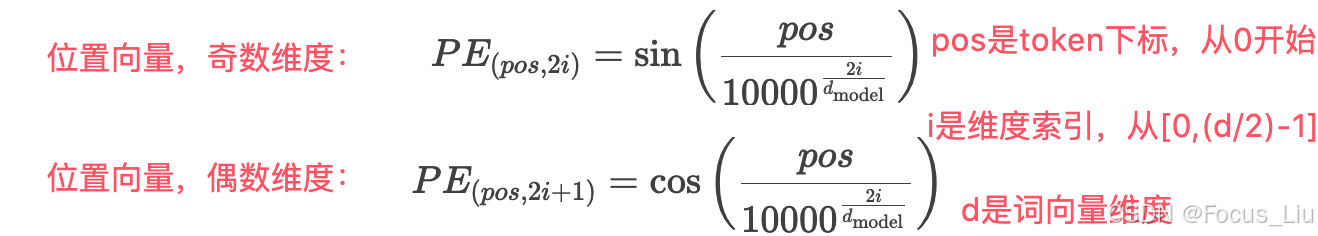
缺点:①相对位置信息捕获能力较差:例如1和5之间差了4个距离,只能靠能通过P1和P5的绝对位置编码间接学习它们之间的相对距离4,而RoPE中,R1*R5直接就是距离4的直接体现。
②处理长序列重叠问题:长序列时,由于周期函数会存在重复的问题,RoPE是对向量进行旋转变换,不依赖于绝对位置值,因此不受训练时序列长度的限制,推理时可以自然地扩展到更长的序列
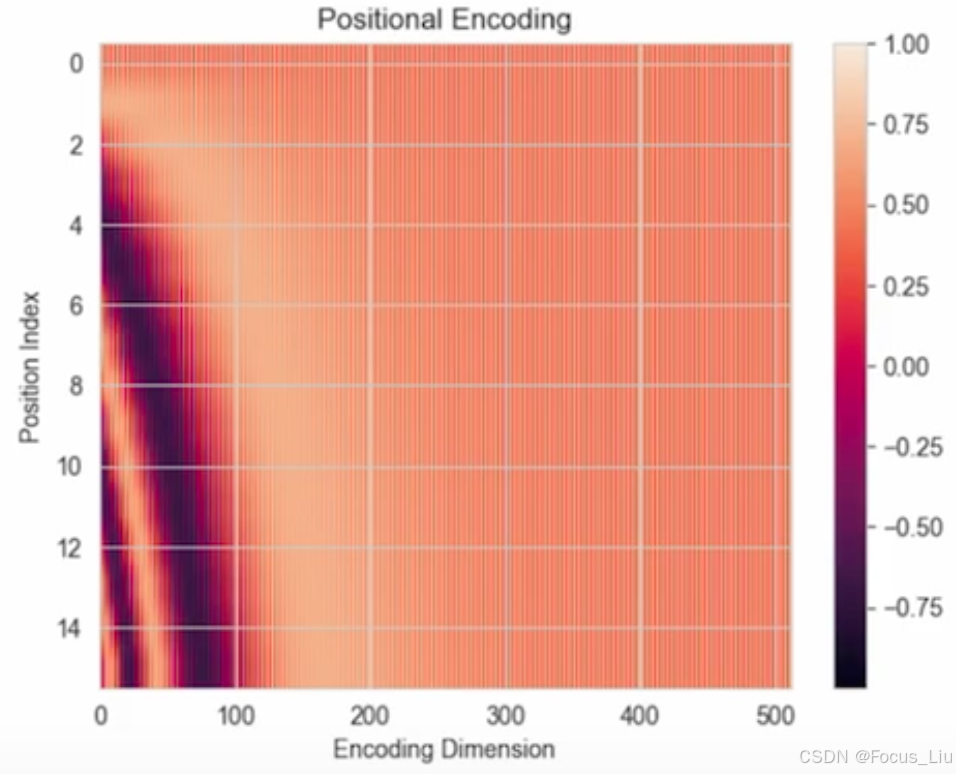
RoPE(Rotary Position Encoding)
介绍:RoPE是一种配合Attention机制能达到“绝对位置编码实现相对位置编码效果”的设计!
如何实现向量的旋转:线代-如何对某个向量[x1,x2]逆时针旋转α度?
 wps电脑版的下载地方怎么找
wps电脑版的下载地方怎么找
 - 副本\241637723116.jpg "WPS office官网下载的地址的方法")
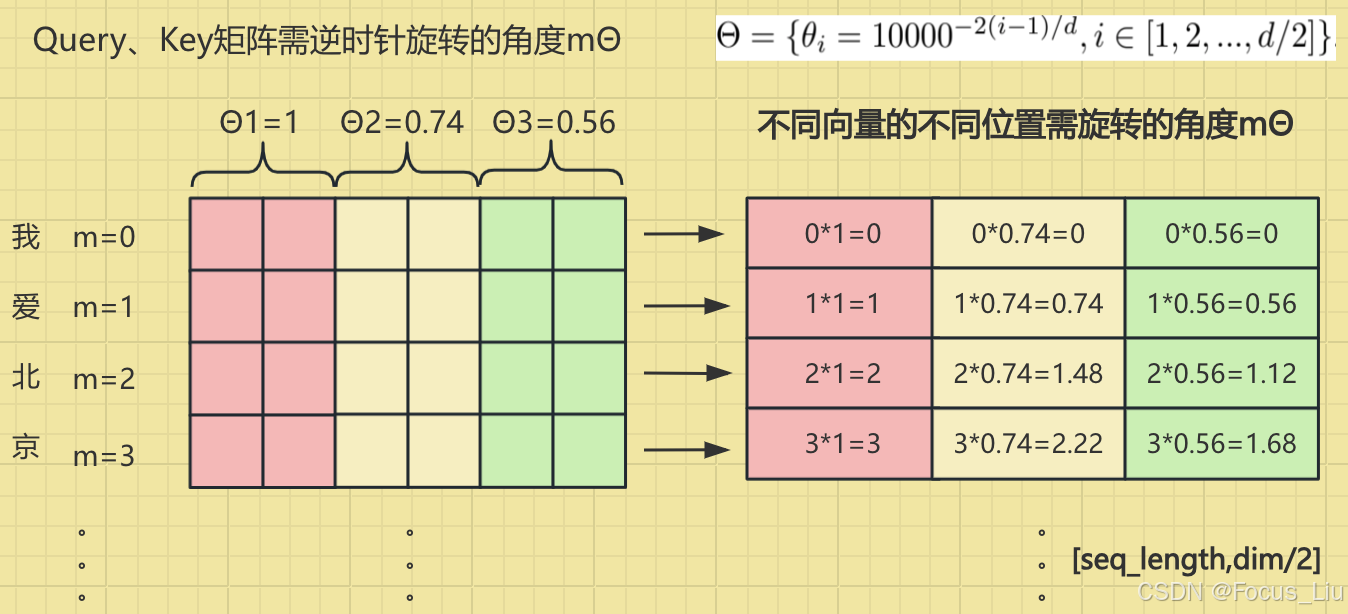
实现流程:把每个token的向量按照两两pair拆分,每对pair维度旋转mθ_i个角度。得到施加位置编码的Q和K。【11】Sinusoidal、RoPE、ALiBi等各类位置信息编码_哔哩哔哩_bilibili
理解:之前评估tokenA和B的相似度,与向量a和b的夹角θ直接相关,现在为了让AB两个词之间距离影响相似度,因此对向量a旋转nβ,b旋转mβ,旋转后A和B的相似度就等于θ+(n-m)β,这样就把绝对位置信息就转换成了(n-m)相对位置信息。
对于一个128维度向量,1~64维旋转的角度较大(高频:用来捕捉短距离依赖),65~128维旋转角度越来越小(低频:用来捕捉长距离依赖),频率越低(也就是角度越小),相对位置影响越小。和原输入的融合计算方式不同:sin-cos位置编码直接和原始输入相加,RoPE位置编码采用类似哈达马积相乘的形式。
RoPE代码实现
原始论文中是将维度0,1,2,3,4,5划分为{0,1},{2,3},{4,5}三组。而在HuggingFace的实现中,可能采用了不同的划分方式,而是分成了{0,3},{1,4},{2,5}三组。其实只要是有一半的是负号就能达到相同的旋转编码效果。
无障碍中文版wps下载网站是多少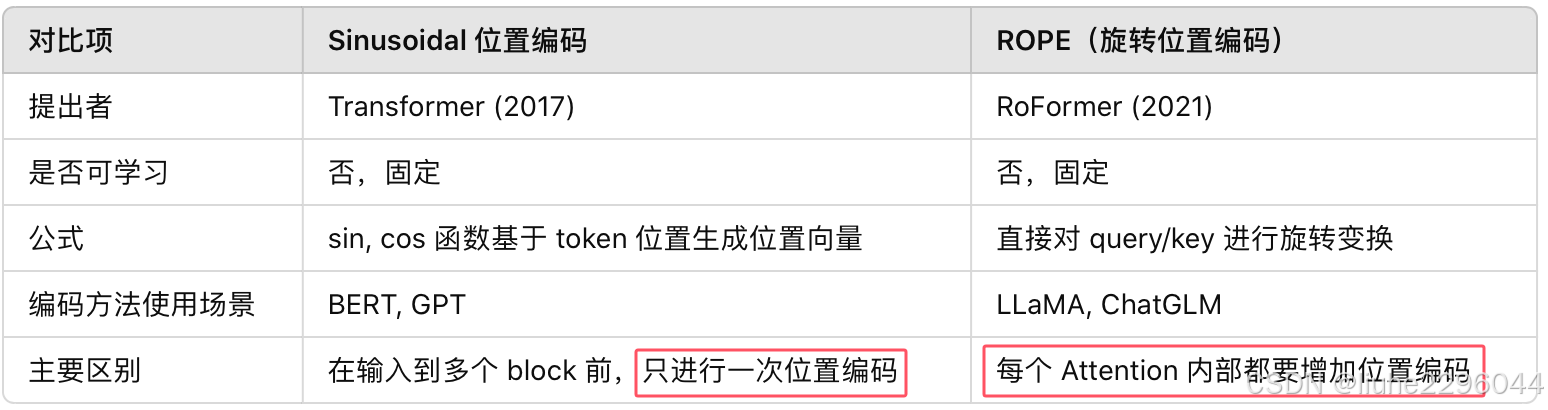
通俗易懂-大模型的关键技术之一:旋转位置编码rope (3)_哔哩哔哩_bilibili
Transformer升级之路:2、博采众长的旋转式位置编码 - 科学空间|Scientific Spaces
背景:如果没有cache,对于标准的Multi Head Attention,无论是训练还是推理时,每新生成一个token,这个token都需要计算他和其他token之间的logtis。因此每次新增token都需要使用W_Q、W_k、W_v矩阵对h进行矩阵变换的计算,得到Q、K、V。
KV Cache与“模型体量”、“模型的输入长度”,“batch_size”有关,在推理过程中动态增长。
KV-cache:在生成第一个 token 时,计算并缓存计算好的K和V,后续生成token时,只需计算当前token的Q,并从缓存中读取之前token的K和V。需要![]() 个缓存大小:2代表K和V都需要一个缓存。n是head的个数,d是单个head的维度,l是有l层个Attention。
个缓存大小:2代表K和V都需要一个缓存。n是head的个数,d是单个head的维度,l是有l层个Attention。
结构优化:MHA、GQA、MQA,如下图,简化Attention结构来提高训练和推理速度,减小KVcache。
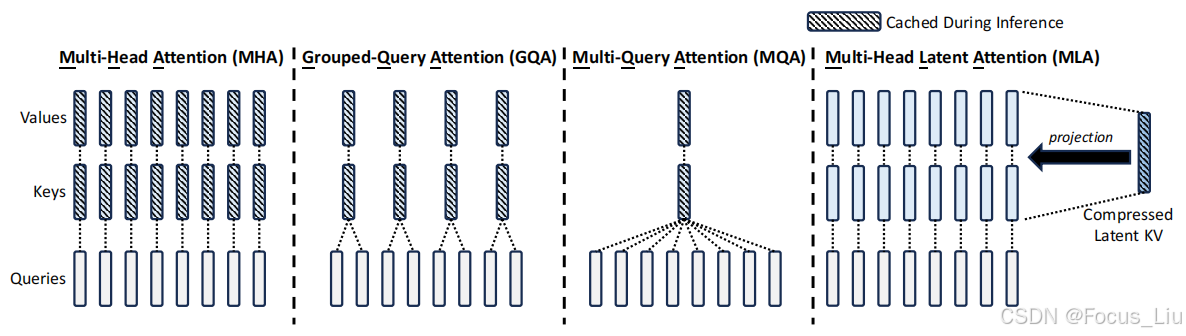
GQA、MQA:在训练阶段就调整Attention的结构,只用n/2组K-V,这样在推理阶段可以大幅减小KV cache。MQA是只用一组K、V。
介绍:就是把Transformer中的Attention后面的一层NN替换成了一个层Moe架构。
模型结构:
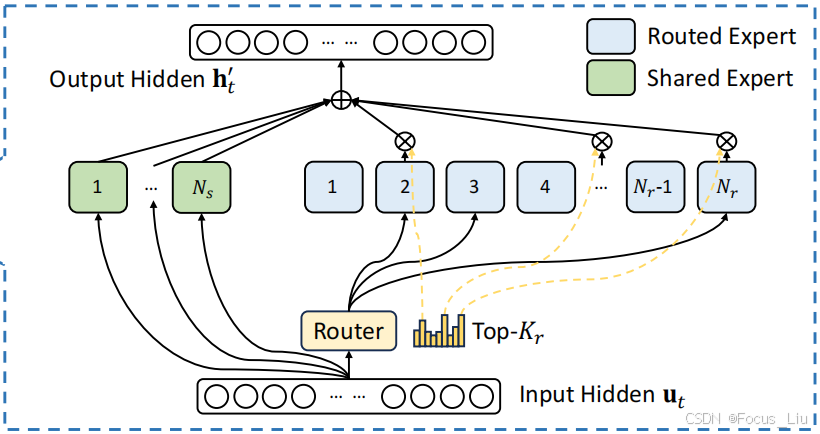
左侧是共享专家,右侧是路由专家,由路由专家从N个专家中选出TopK个。最后共享专家们和路由专家们做element-wize加和。
公式:
Transformer中![]() ,通常是上采样升维到2048,然后下采样到512。最新的官网wps下载地方Moe是对FFN进行了替换。
,通常是上采样升维到2048,然后下采样到512。最新的官网wps下载地方Moe是对FFN进行了替换。

代码实现(SwiGLU结构):
原始FFN和SwiGLU-FFN结构对比:
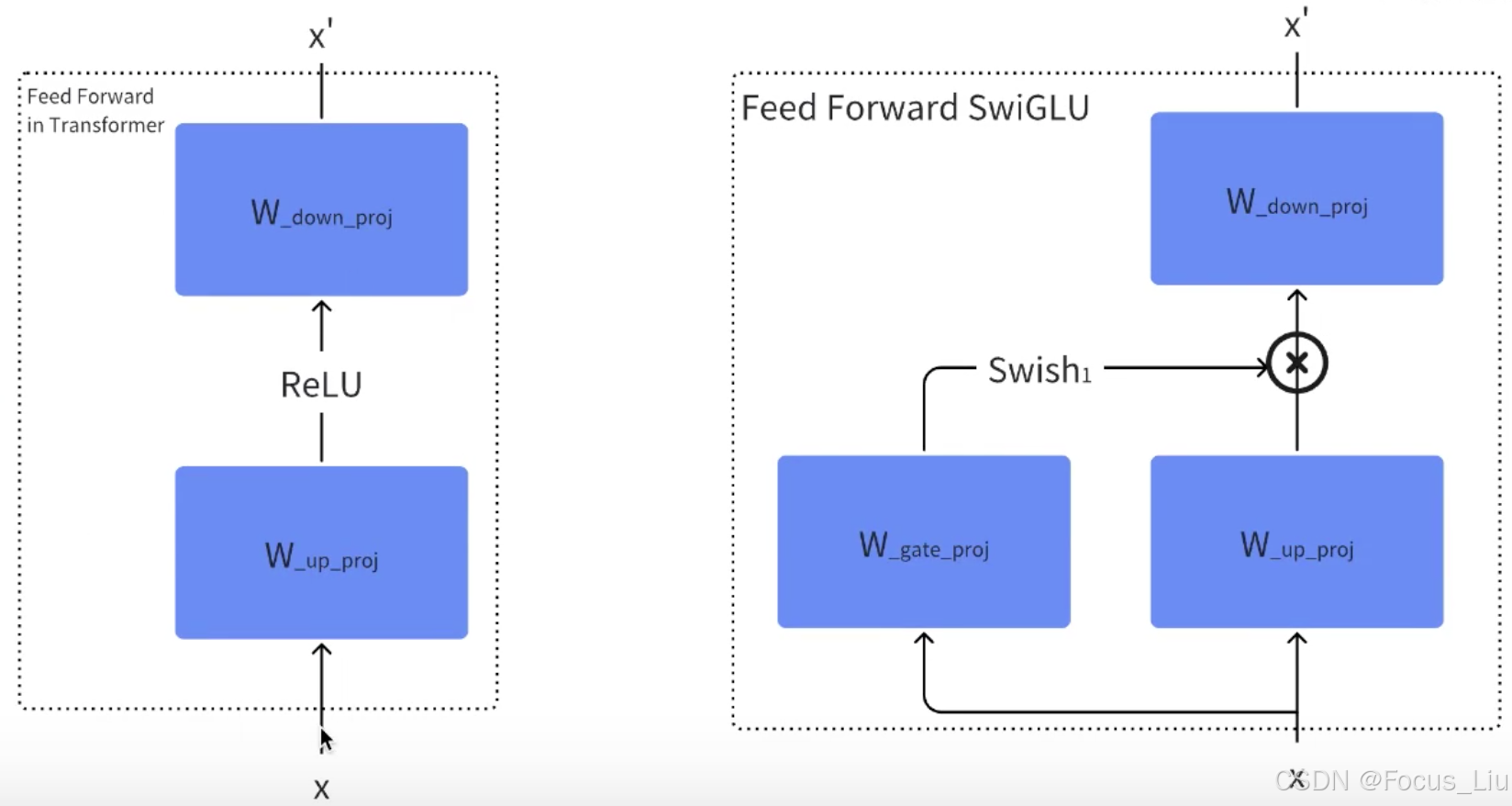
例如:FFN通常同时上采样升维到2048,然后relu激活再下采样降维到512。
3分钟理解SwiGLU激活函数_哔哩哔哩_bilibili
激活函数对比:
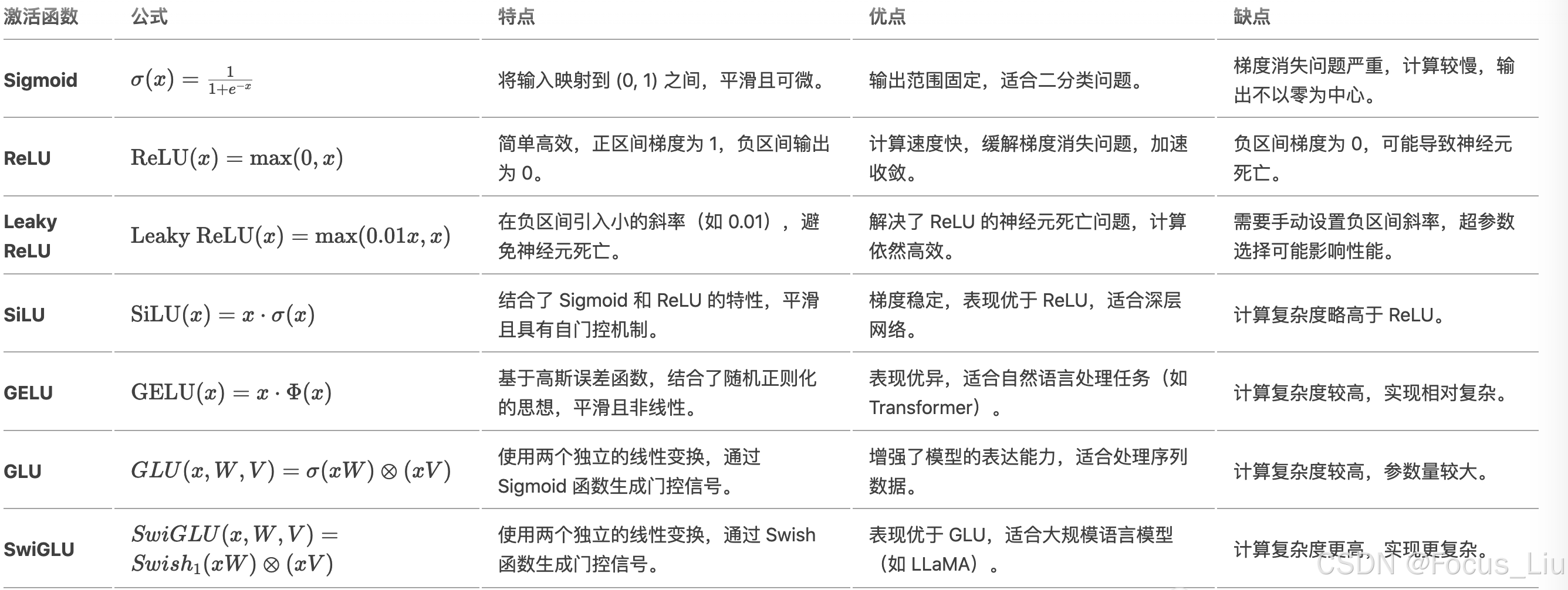
GLU和SwiGLU带有参数,这两个更像是网络结构。SwiGLU就是机遇GLU把sigmoid换成了SiLU激活。
路由策略:
输入为[512,7168],这里的512是batch*seql_len得到的将输入映射成专家数,[512,256] 有512个词,每个词有256个专家的w。对专家分成8组,得到[512,8,32]计算每组top2个专家的得分得到top4组[512,4]从top4组的专家当做全部池子(4*8),抽取top8个专家的下标和权重[512,8]。
负载均衡
问题:不同目标的专家权重都集中在某一个expert,也称极化问题。
解决方案:
在softmax权重使用10%的dropout(每个专家被丢弃的概率是10%)。辅助损失:loss增加α*专家输出的logtis的平均值(过大的辅助损失会损害模型性能)V3优化-不带辅助损失的负载均衡(官网最新版的wps下载的地方是什么MoE)
V3优化-不带辅助损失的负载均衡(Auxiliary-Loss-Free Load Balancing)
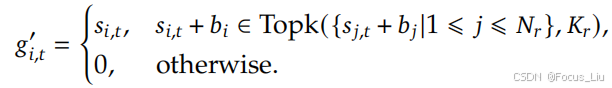
在选r个路由专家的时候,相当于增加了一个可以在训练阶段可调节(根据专家负载)的超参。注意,只有在选路由专家的时候才增加这个权重b,而在做路由专家加权求和的时候,仍然使用不带权重b进行加权求和。(个人理解就是某些expert可以不擅长某些样本,但是不能一点不学习啊)
最新的官网wps下载地方MoE和CGC的区别:CGC是对共享和独有专家进行weight sum,官网最新版的wps下载的地方是什么的门控筛选出r个做加权求和,最后再与共享专家element-wise求和将所有专家分成D组,每组的专家放到同一个device上。671B的模型有256个路由专家,每次激活8个。
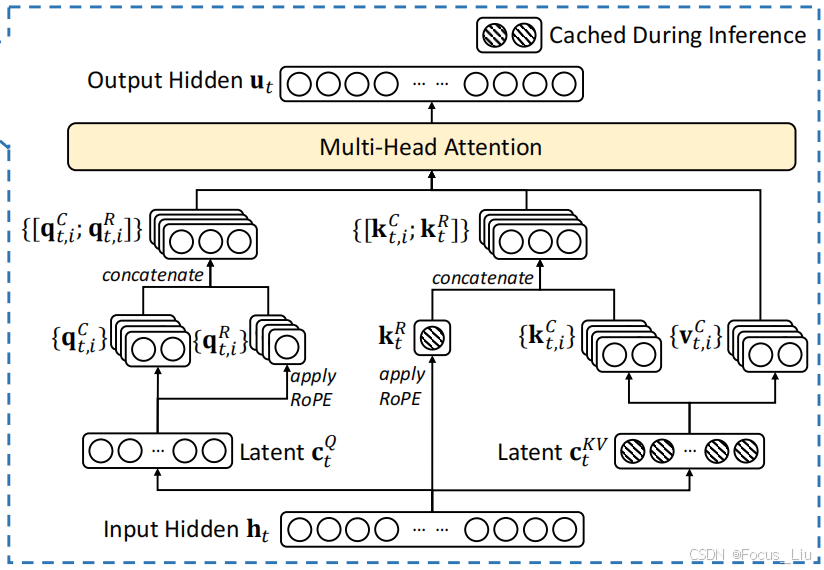
优化Attention结构
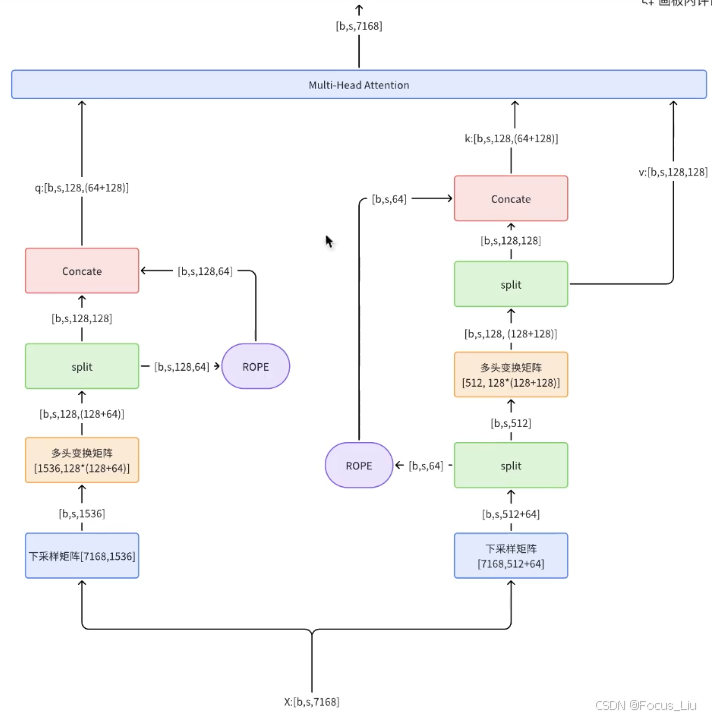
答:“通过将KV映射到低维度的向量c来实现”,如果是用标准的Attention结构MHA,在推理生成每个新token的时候,每次都要计算全部历史token在Attention的K和V。MLA把KV借用了Lora结构的思想,先映射到一个低维度隐层c,然后再映射回原来的维度dim。在缓存时,无需再缓存完整的K和V,而是缓存一个隐向量c,隐向量经过两个不同的升维矩阵,得到新的k和vwps 的官网下载地址(wps官网下载手机版)。这样就从原来的一个长K、V两个向量,变成一个短的隐向量c。
推理阶段合并矩阵-Absorb
最新官网的wps的下载的入口在哪呢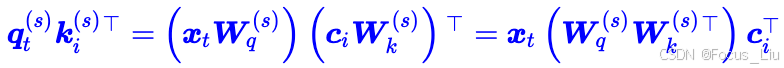
在推理阶段,我们还可以进行额外的优化,推理时,我们是要算q矩阵和k矩阵的logits,即"q由输入x经过矩阵Wq线性变换而来,k由隐向量c经过Wk升维而来"。这样就通过数学推到把两个固定的矩阵合并成一个矩阵,我们把这个矩阵看成新的Wq',这样就变成了"q由输入x经过矩阵Wq'线性变换而来,k由隐向量c升维而来"。同理,“v由隐向量c经过Wk升维而来”,生后面还有一个投影矩阵,因此这个Wk也可以被后面吸收。这样就减少了矩阵计算。
合并矩阵后如何处理RoPE
上面的公式之所以合并是在RoPE的情况,RoPE已经成了一个大模型标配的位置编码,但是由于RoPE是在Attention内部对q和v进行施加旋转,也就是![]() ,因此不同位置的旋转后的矩阵不一样。(例如输出第一个token时Ri等于1,但是当输出第二个token时,Ri不在是1了,而且Ri具体是多少无法根据当前位置进行推算,你只知道离token越远token对你的影响会越“xx”)。
,因此不同位置的旋转后的矩阵不一样。(例如输出第一个token时Ri等于1,但是当输出第二个token时,Ri不在是1了,而且Ri具体是多少无法根据当前位置进行推算,你只知道离token越远token对你的影响会越“xx”)。
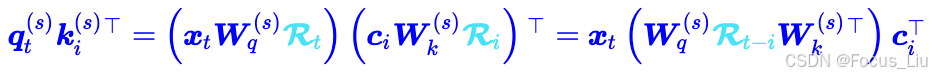
因此,他选择新增一个小维度对输入进行变换,然后得到一个维度较小的k,来实现Rope。
缓存向量有两部分:一隐向量c和一个经过rope的k。Q的输入也改为了低秩投影形式。主要是为了减少训练期间参数量和相应的梯度。注意一点就是,k的位置编码是基于h做 而q的位置编码是基于c来做的。MLA在推理阶段做的这个转换,虽然能有效减少KV Cache,但其推理的计算量是增加的。由于MLA的KV cache与隐向量相关而与h无关,所以可以增大h来增加计算量和提升模型能力,但不会增加KV Cache,不会带来速度瓶。
缓存与效果的极限拉扯:从MHA、MQA、GQA到MLA - 科学空间|Scientific Spaces
全网最细!最新的官网wps下载地方MLA 多头隐变量注意力:从算法原理到代码实现_哔哩哔哩_bilibili
为什么能提推理高速度?
MLA在推理阶段做的这个转换,虽然能有效减少KV Cache,但其推理的计算量是增加的。那为什么还能提高推理效率呢?这又回到“瓶颈”一节所讨论的问题了,我们可以将LLM的推理分两部分:第一个Token的生成(Prefill)和后续每个Token的生成(Generation),Prefill阶段涉及到对输入所有Token的并行计算,然后把对应的KV Cache存下来,这部分对于计算、带宽和显存都是瓶颈,MLA虽然增大了计算量,但KV Cache的减少也降低了显存和带宽的压力,大家半斤八两;但是Generation阶段由于每步只计算一个Token,实际上它更多的是带宽瓶颈和显存瓶颈,因此MLA的引入理论上能明显提高Generation的速度。
官网最新版的wps下载的地方是什么 V3中MTP的设计主要是为了训练过程能加速收敛,更充分的使用训练样本。
MTP的意义:
一次学习多个位置的label,提高样本利用率和训练速度。推理阶段一次生成多个token,能加速推理。能学习长距离的依赖关系。
Meta's MTP:
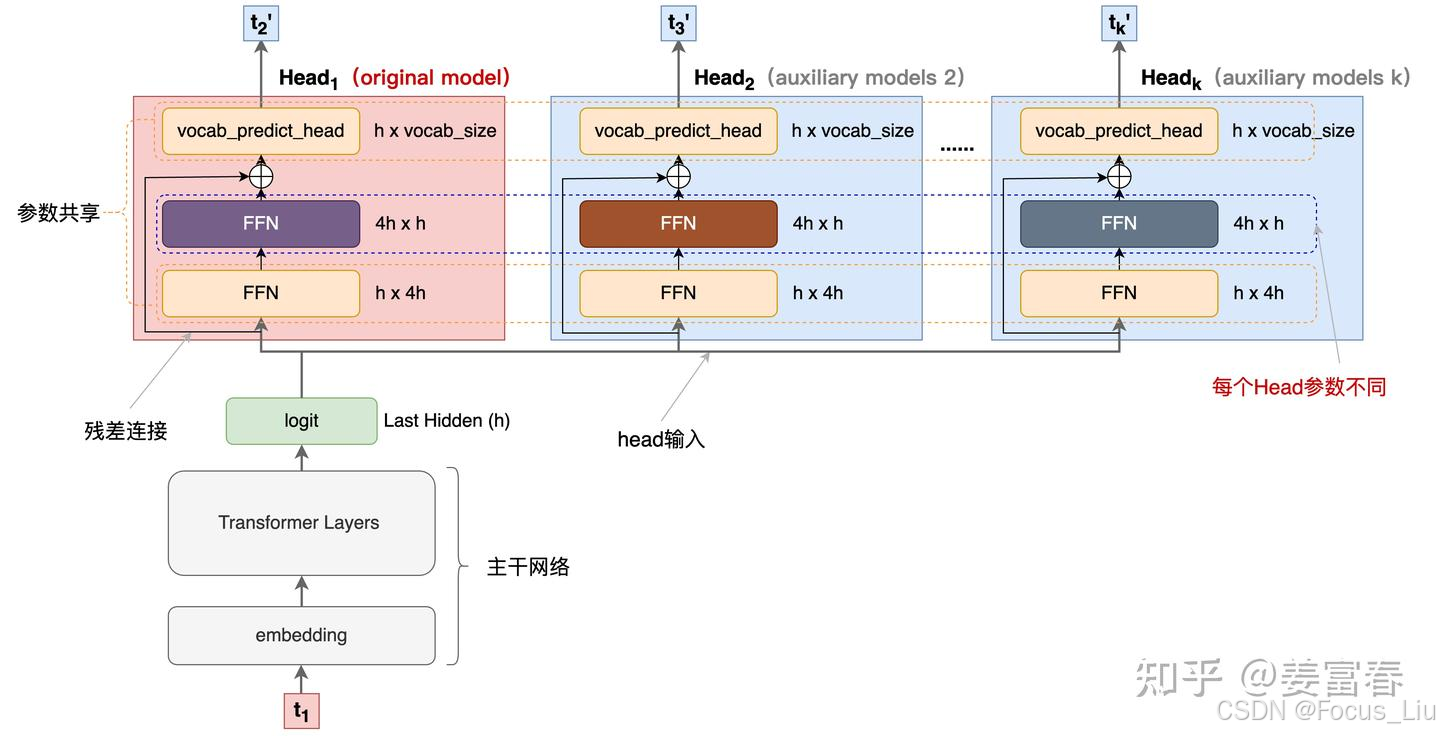
Meta MTP如何推理:
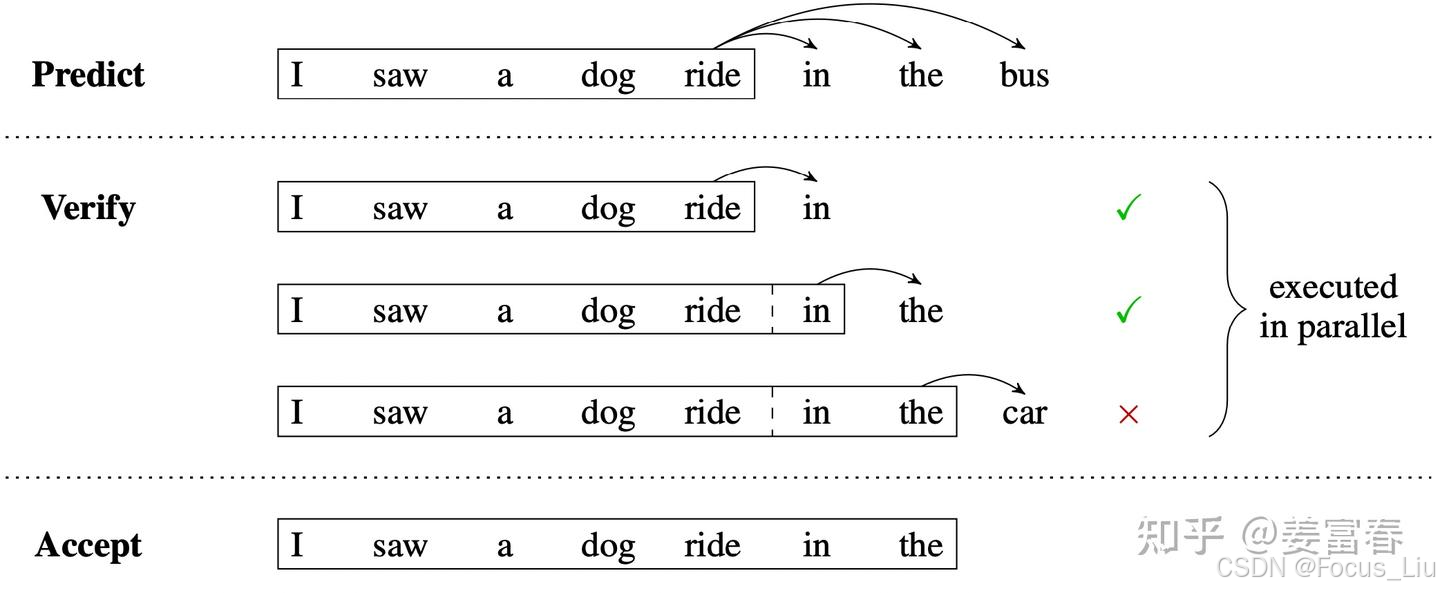

最新的官网wps下载地方 MTP
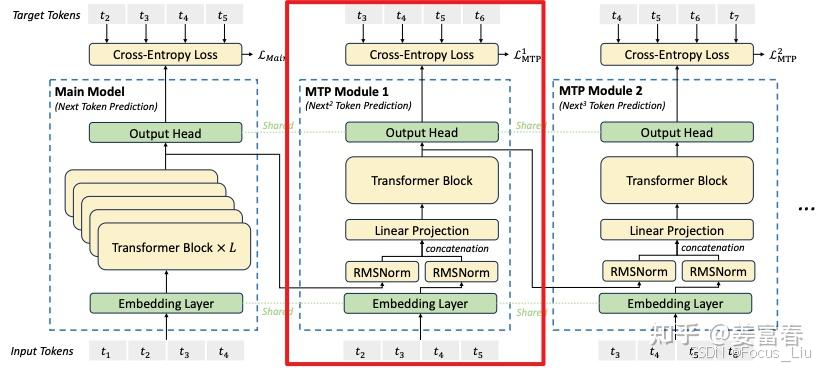
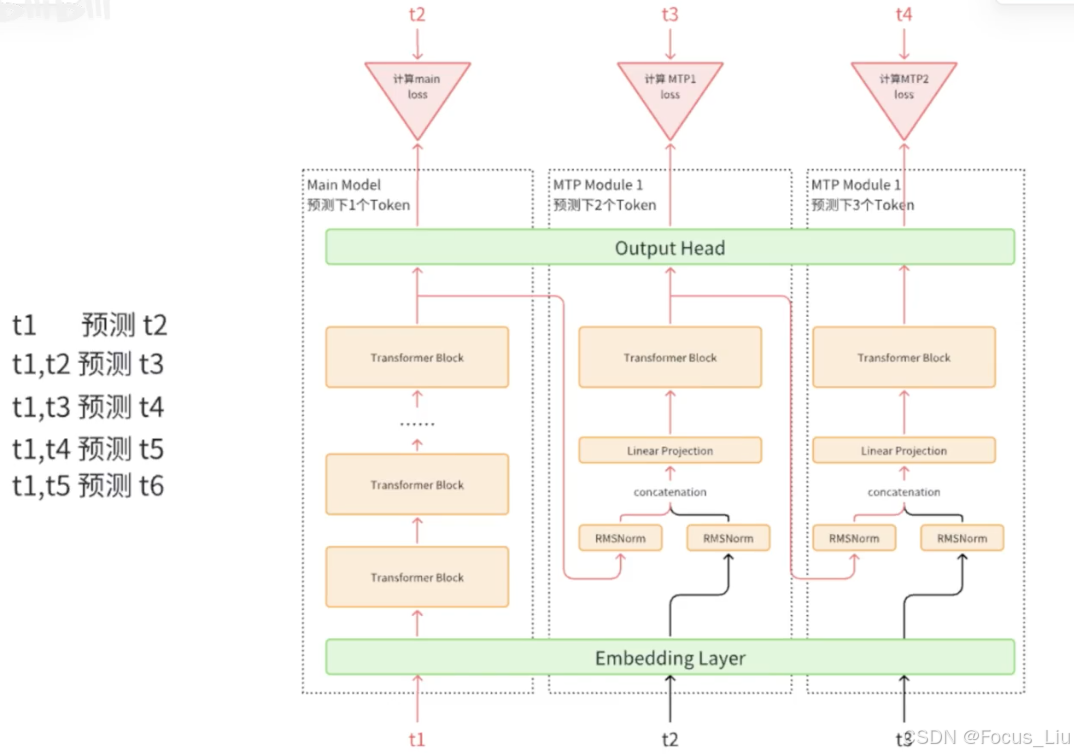
使用Teacher Forcing训练模型。(正常应该是拿上一个状态的输出(也就是图中的 t2′ )作为输入,但在序列建模训练中,直接用样本中的ground truth作为输入,效果会更好。因为如果拿预估的状态 t2′ 作为输入,随着时间的推移,预估错误会持续累加,导致效果有损。)
推理方式:
方法1:直接把MTP Model头全部删掉,模型变成了一个Predict Next Token的 Main Model。然后部署模型做推理,这个就跟正常LLM模型推理一样。没有什么加速效果
方法2:保留MTP Model 做self-speculative decoding,这样充分使用多Head预测能力,提升推理加速性能。类似2.1中介绍的三阶段
ppt可以参考:https://zhuanlan.zhihu.com/p/18056041194?utm_psn=1863031551043960832
转移另一篇博客:RLHF-GRPO-CSDN博客
其他
R1-论文讲解:COT微调数据集:
参考资料:
官网最新版的wps下载的地方是什么 R1与kimi1.5 硬核解读_哔哩哔哩_bilibili
终于把最新的官网wps下载地方-R1核心算法GRPO讲明白了!附思维导图!从强化学习0基础->PPO->GRPO,适合所有人学习,如何入门到精通?少走99%的弯路!_哔哩哔哩_bilibili
[LLM+RL] 理解 GRPO 公式原理及 TRL GrpoTrainer 代码实现(advantage 与 loss 计算)_哔哩哔哩_bilibili
分组量化:
全网最细!官网最新版的wps下载的地方是什么MTP 多Token预测:从算法原理到代码实现_哔哩哔哩_bilibili
Hi,大家好呀~我是一枚对AI十分感兴趣的一枚程序wps office免费版下载网站在哪员,一直在思考如何能够利用openAI技术,搞一搞自己的wps office免费版的下载的网站是什么小副业。去年2月,chatwps office 的官方的下载的网址怎么找(wps官网下载电脑版)gpt一夜爆火。没想到wps官网的下载的地址fwps office 官方下载的网址怎么找(wps官网下载免费版)0c;今
最新官网wps的下载网址哪里有 Small PDF合并分割软件wps office的免费版下载的地址在哪里主要运用在将PDF文档进行按wps office 的官方的下载网站是多少需求分割、合并,截取或结合成有用的文档,再进行后续的转换或者编辑等。利用Small PDF合并wps官网的下载网站在哪(wps office下载手机)分割软件可以有效对文件进行二次整合的综合解决。  
wps最新的官方下载网址哪里有wps最新的官方的下载网站ChatGPTwps电脑版下载的网址 4.0 目前是收费模式,但微软已经在Skype中集成了一个 免费的Bing聊天机器人,它可以和你进行 wps官网下载的入口在哪有趣和有用的对话,帮助你找到你想要的信息,也可以为你创造一些富有想象力和创新性
SIMA是DeepMind推出的一个wps 官网下载的地址在哪(wps下载电脑版没反应怎么办)通用AI代理,可以在广泛的游戏世界中理解并执行任务。以下是SIMA的详细介绍:wpswps 的官网的下载地方怎么找 官网下载的地址在哪(wps下载电脑版没反应怎么办)官方最新中文版wps的下载的地方哪里有SIMA是一个多 wps官网的下载的地方在哪世界AI
أفضل نماذج الذكاء wps office的免费版下载的网站怎么找 الاصطناعي في مكان واحد. قارن الإجابات بين 官网最新版的wps下载的地方是什么-R1، o3-mini، o1، GPT-4o wps office的免费版的下载入口在哪(wps官网是什么)، Claude، Gemini،wps电脑版的下载的网址的方法
Nejlepší AI wps office 官方的下载的网址怎么找 modely na jednom místěwps office 官方的下载的网址怎么找. Porovnejte odpovědi mezi wps office免费版的下载网站怎么找 官网最新版的wps下载的地方是什么-R1, o3-mini, o1, GPT-4o, wps的电脑版下载的地方在哪 Claude, wps office 的官方下载网站怎么找 Ge