
wps免费版下载的网址是什么
官网最新版的wps下载的地方是什么模型微调(超详细实战篇)
**
官网最新版的wps下载的地方是什么是由 深度求索 团队开发的大语言模型,本实验将基于官网最新版的wps下载的地方是什么-llm-7b-chat模型,在EmoLLM数据集进行微调,实现大模型能够以心理医生的口吻来回答我们的问题。
本实验基于transformers和openMind均已实现本次微调,代码均可在github链接上查看。
通过本次实验,你不仅能够完成多轮对话数据的微调,还能掌握这些方法,并将其迁移到其他微调实验中,独立进行高效的模型调优。

👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]👈
写在前面
本次实验同时适配transformers和openMind,由于openMind缺少数据处理的函数,下面实验手动添加即可,其他部分和基于transformers的代码一致。
2.1 基本概念
1、openMind Library—>Huggingface Transformers
openMind Library类似于transformers的大模型封装工具,其中就有AutoModelForSequenceClassification、AutoModelForCausalLM等等模型加载工具以及像TrainingArguments参数配置工具等等,原理基本一样,不过对NPU适配更友好些。

openMind Library是一个深度学习开发套件,通过简单易用的API支持模型预训练、微调、推理等流程。openMind Library通过一套接口兼容PyTorch和MindSpore等主流框架,同时原生支持昇腾NPU处理器,同时openMind Library可以和PEFT、DeepSpeed等三方库配合使用,来加速模型微调效率。
2、魔乐社区—>HuggingFace
魔乐社区类似于huggingface这种模型托管社区,里面除了torch的模型还有使用MindSpore实现的模型。transformers可以直接从huggingface获取模型或者数据集,openMind也是一样的,可以从魔乐社区获取模型和数据集。
2.2 实验环境搭建及实验代码、结果
2.2.1 环境设置
在运行代码前,需要先配置环境,由于本次实验对比各个参数结果比较多,所以对显存要求稍微高点,具体环境配置如下:
GPU:40GB左右
Python:>=3.8
2.2.2 数据预处理
本次微调目的是使得大模型能够以医生的口吻来回答我们的问题,因此需要与心理健康有关的数据集资料。
下载数据
本项目使用一个EmoLLM-心理健康大模型中使用的数据集(该数据集已经进行数据清洗,在保证质量的同时,通过调整阈值减少因错误匹配而丢失重要数据的风险。):EmoLLM-datasets
(https://github.com/SmartFlowAI/EmoLLM/tree/main/datasets)
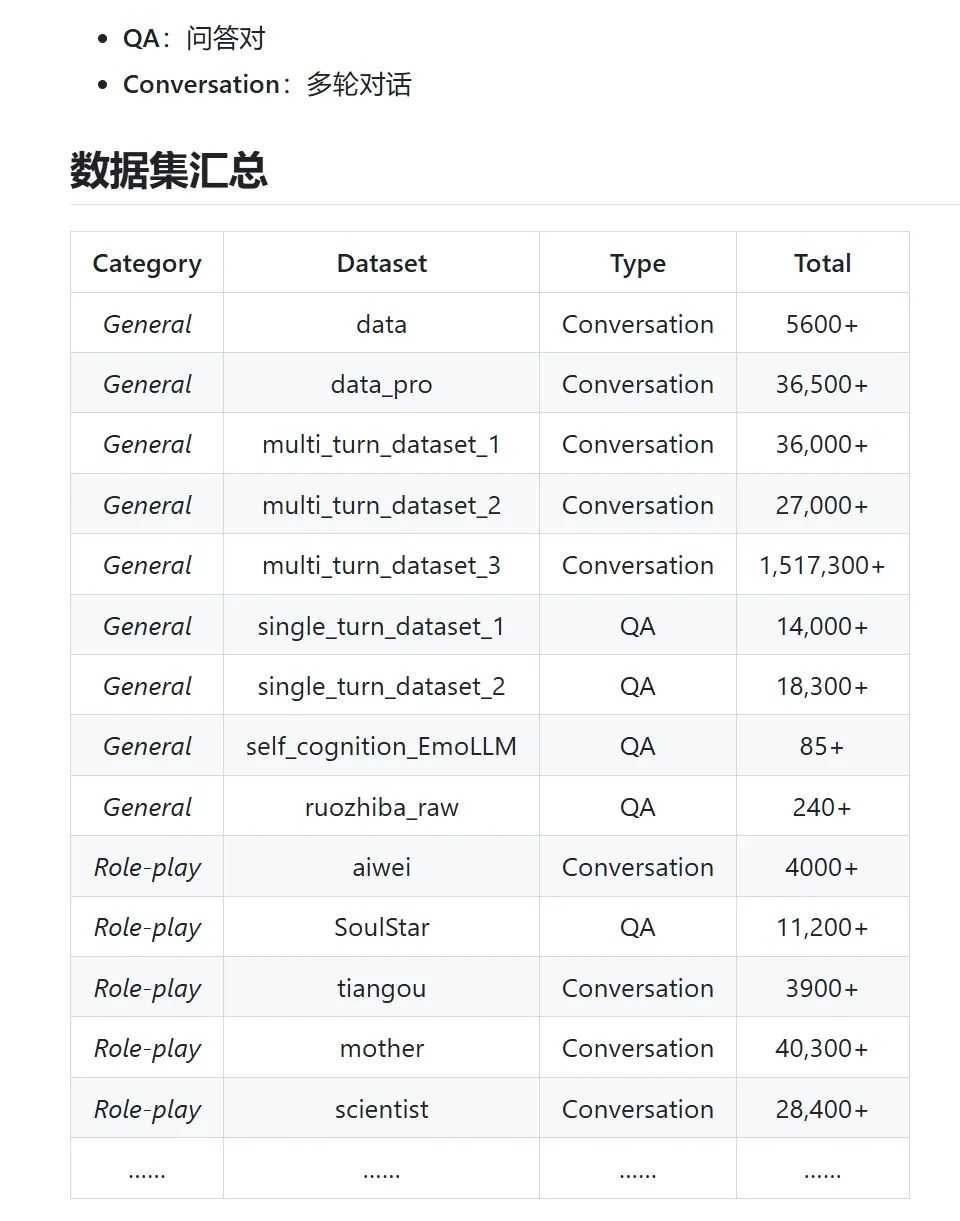
数据集内容如下:
在训练前,我们需要将数据进行预处理,将数据集的内容进行数据映射,得到input_ids、attention_mask、labels三个映射目标,同时对数据填充到最大长度,并且转换成张量格式。
数据映射
❗注意:
这里可能会根据每个模型的不同做修改,如果不按照每个模型对应的格式训练,而是按照自己编写的格式进行训练,结果可能会出现由于max_length比较大使得回答停不下来,一直生成句子。
那么该如何确定训练文本格式?其实在每一个模型的tokenizer_config文件中已经给出模板。
比如官网最新版的wps下载的地方是什么的模板如下:
如果模板看的有点抽象的话,可以直接参考Llama-Factory中官网最新版的wps下载的地方是什么模型对应的模板:WPS office的电脑版的下载方法
https://github.com/hiyouga/LLaMA-Factory/blob/main/src/llamafactory/data/template.py

数据封装
 - 副本\2000000_57.jpg "wps免费版下载的网址是什么")
⚠️注意:
由于openMind缺少数据封装的函数,因此这部分代码需要我们手动添加,transformers直接调用即可。
transformers:
openMind:
2.2.3 设置lora参数
2.2.4 设置训练参数
2.2.5 设置可视化工具SwanLab
SwanLab是一款完全开源免费的机器学习日志跟踪与实验管理工具,为人工智能研究者打造。有以下特点:
基于一个名为swanlab的python库
可以帮助您在机器学习实验中记录超参数、训练日志和可视化结果
能够自动记录logging、系统硬件、环境配置(如用了什么型号的显卡、Python版本是多少等等)
同时可以完全离线运行,在完全内网环境下也可使用
代码如下:
2.2.6 设置训练器参数+训练
在微调Transformer模型时,使用Trainer类来封装数据和训练参数是至关重要的。Trainer不仅简化了训练流程,还允许我们自定义训练参数,包括但不限于学习率、批次大小、训练轮次等。通过Trainer,我们可以轻松地将这些参数和其他训练参数一起配置,以实现高效且定制化的模型微调。
这里我们需要以下这些参数,包括模型、训练参数、训练数据、处理数据批次的工具、还有可视化工具
2.2.7 保存模型
这里保存了模型的权重、配置文件和词汇表,确保你可以在之后重新加载并使用该模型进行推理或继续训练。模型的优化器状态、学习率调度器等其他信息如果需要保存,则需要显式调用其他相关方法,如 trainer.save_state()。
2.2.8 合并模型权重
保存下来的仅仅是模型的权重信息以及配置文件等,是不能直接使用的,需要与原模型进行合并操作,代码如下:
完整代码的话可以直接参考github上的代码,这里记录一下每一部分文件的含义
所有结果均可在SwanLab中得到,下面我们可以分别观察下:
https://swanlab.cn/@LiXinYu/官网最新版的wps下载的地方是什么-llm-7b-chat-finetune/overview

学习率lr
学习率是微调LoRA(Low-Rank Adaptation)模型时的一个关键超参数,它对模型的训练动态和最终性能有着显著的影响。
收敛速度:学习率决定了模型在损失函数梯度方向上更新的步长。一个合适的学习率可以加快模型的收敛速度,而过高或过低的学习率可能导致收敛速度慢或不收敛。
稳定性:果学习率设置得过高,可能会导致梯度更新过于激进,引起训练过程中的不稳定性,如梯度爆炸。相反,如果学习率过低,则可能导致梯度更新过于保守,影响模型的学习能力。
对超参数敏感程度:LoRA对学习率非常敏感。LoRA的最佳学习率比全参数微调的学习率要高一个数量级。
泛化能力:适当的学习率可以帮助模型在训练集上学习到有用的特征,同时避免过拟合。
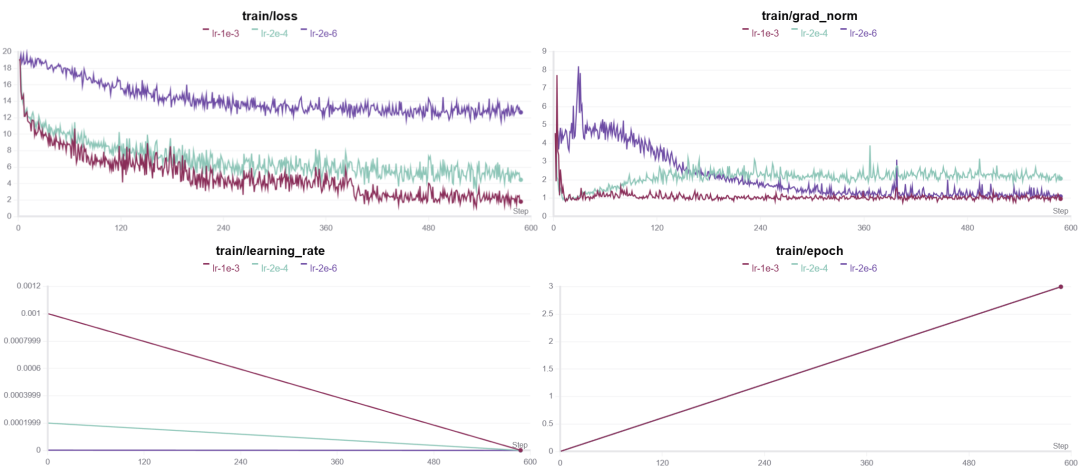
哪种情况下的lr值比较合适?
1、从图中我们可以看到从loss和grad_norm曲线的变化上看,当lr=2e-6的时候明显由于学习率过小,损失和梯度范数的变化都非常缓慢,意味着模型更新太慢,难以有效学习。wps免费版下载的网站在哪里
2、当学习率较高,lr=1e-3的时候,损失和梯度范数的波动较大,虽然从图中可以看出其能优先达到最优值,但是由于模型更新参数时比较激进,可能会引起训练的不稳定性,比如梯度爆炸,事实上,在最开始的steps里确实出现了梯度爆炸的情况,只不过后来慢慢的调整过来了。因此该学习率还是过大了。wps的官网下载网站
综上所述,梯度取值在2e-4~1e-3的范围内对该模型以及数据集情况较好。
如果再往大了取值的话会很明显的观察到梯度爆炸的情况,具体如下图所示,lr=1e-2的情况:
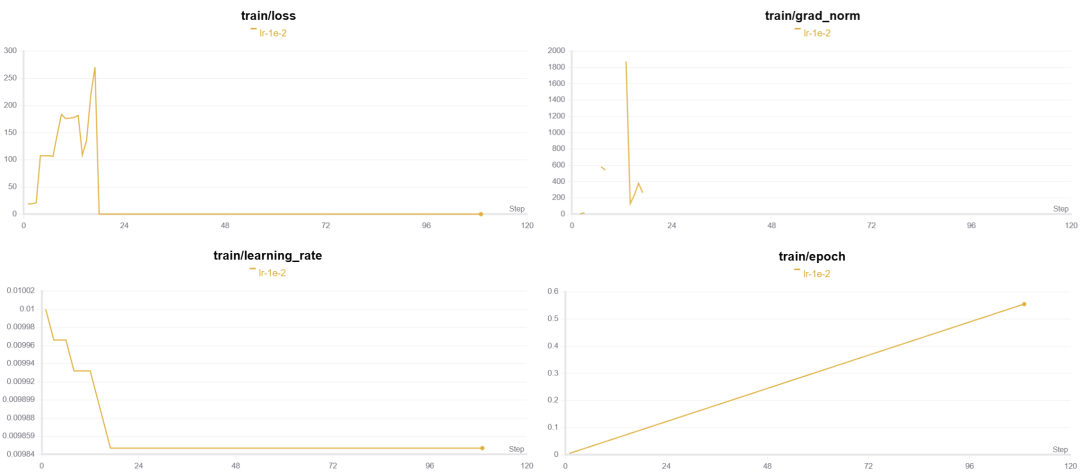
⚠️因此优先调节学习率选择合适的值是非常重要的,可以节省很多时间
我们具体也可以从推理结果上来查看效果:
从结果上看,学习率设置正确的话推理结果确实比想象中要好很多,而且可以节省很多训练资源。
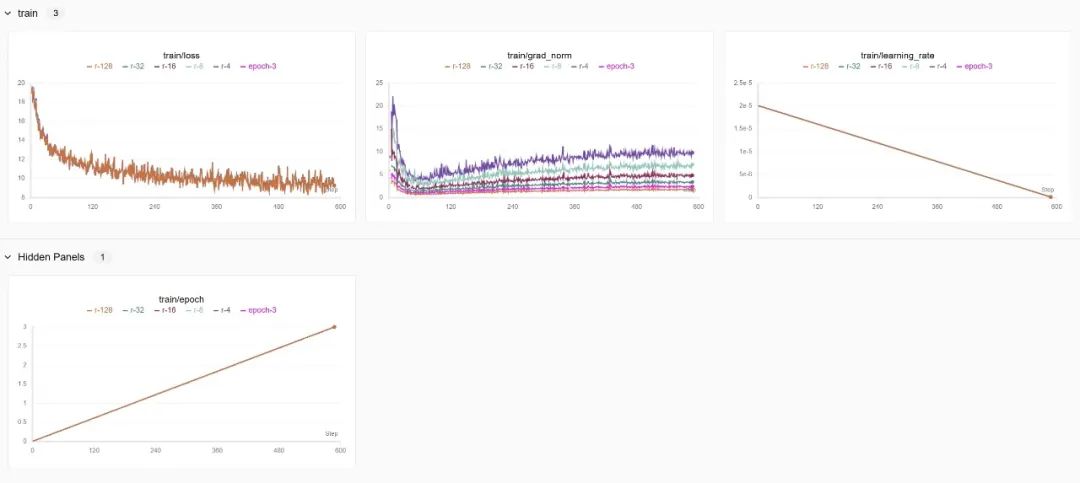
3.1 lora的秩r
下图表示不同r的情况下模型loss还有梯度grad_norm变化的曲线,其中epoch-3表示的是r=64的结果
总结:
由于这里设置的学习率低了点,所以模型收敛速度比较慢,loss曲线均具有相同的下降趋势并且基本一致,但是秩越高,梯度范数越低,原因有以下几点:
数值稳定性:在数值计算中,较高的秩可能有助于提高计算的稳定性,这是因为高秩矩阵在数值运算中更稳定。
局部最小值或鞍点:在优化过程中,模型可能陷入局部最小值或鞍点。较高的秩可能导致模型在参数空间中的不同区域收敛,这些区域可能具有相似的损失值,但梯度方向和大小不同,这可能导致梯度范数的降低,因为模型在这些区域的梯度更新更小。
优化算法的效率:不同的秩可能导致优化算法在参数空间中的搜索路径不同。较高的秩可能允许模型在参数空间中更平滑地移动,从而减少梯度的波动,这可能导致梯度范数的降低,因为模型在优化过程中更加稳定。
梯度稳定性:在深度学习中,梯度的稳定性对于训练过程至关重要。较低的梯度范数通常意味着梯度更新更加稳定,不容易出现梯度爆炸或消失的问题。当秩较高时,模型可能更容易找到损失函数的平滑区域,从而使得梯度更新更加稳定,梯度范数较低。
由于lora微调的时候本身就冻结了大部分参数,所以即使r增加,但是显存的占用并不会显著增加,因此这部分可以忽略不计,只需要在合适区间上考虑loss和grad_norm的变化即可。
3.2 lora的缩放因子α
缩放因子(alpha)用于调整低秩矩阵更新的幅度,以确保这些更新不会过大或过小,从而影响模型的稳定性和收敛性。
缩放因子(Alpha)的影响
更新幅度的调节:缩放因子alpha用于调整低秩矩阵更新的幅度。在LoRA中,原始权重矩阵W被分解为W0 + W_rank,其中W_rank = A * B,A和B是低秩矩阵。如果alpha设置得过大,可能会导致梯度更新过于激进,从而引起训练过程中的不稳定性;如果设置得过小,则可能导致更新过于保守,影响模型的学习能力。
梯度稳定性:适当的alpha值有助于保持梯度的稳定性。如果alpha过大,可能会导致梯度爆炸;如果过小,则可能导致梯度消失。
模型收敛性:alpha的值直接影响模型的收敛速度和稳定性。一个适中的alpha值可以帮助模型更快地收敛到一个较好的解。
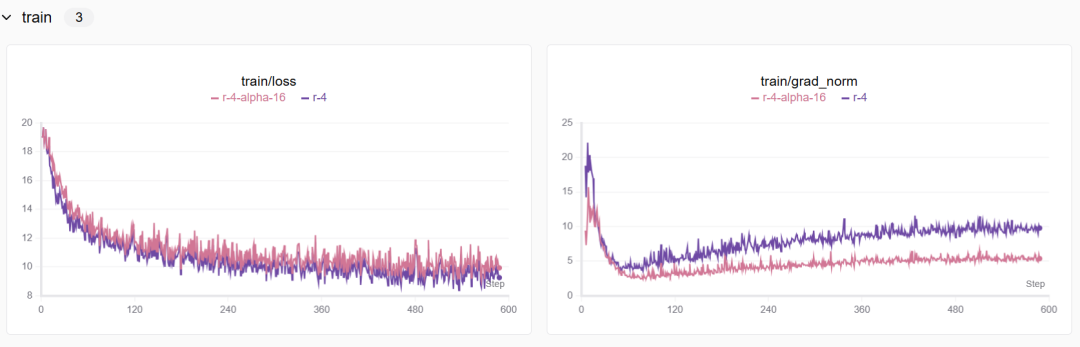
为什么alpha=16比alpha=32模型收敛效果更好一些?:
更新幅度适中:alpha=16提供了一个适中的更新幅度,使得模型在训练过程中能够稳定地学习和收敛。
避免梯度爆炸:alpha=32可能过大,导致梯度更新过于激进,从而引起训练过程中的不稳定性。
优化算法的适应性:不同的alpha值可能与优化算法的适应性有关。alpha=16更好地适应了所使用的优化算法,从而促进了模型的收敛。
总的来说,选择合适的alpha值需要考虑模型的稳定性、收敛速度以及训练过程中的梯度行为。通过实验和调整,可以找到最适合特定模型和任务的alpha值。
然后多次实验的结果如下,其中没有标记的alpha=32,可以参考下:

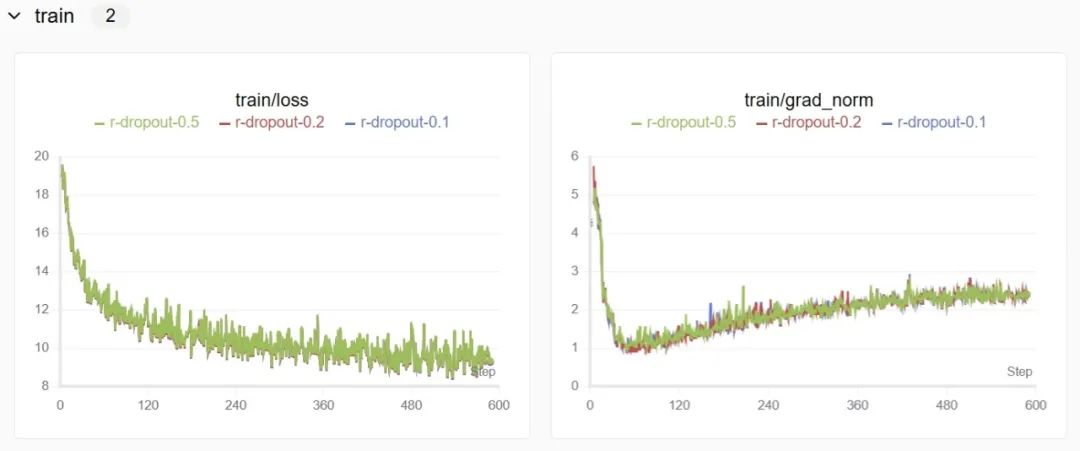
3.3 lora的正则化参数dropout
在神经网络训练中,模型往往倾向于“记住”训练数据的细节甚至噪声,导致模型在新数据上的表现不佳,即过拟合。为了解决这一问题,Dropout 应运而生。通过在训练过程中随机丢弃一部分神经元,Dropout 能减少模型对特定神经元的依赖,从而提升泛化能力。
这部分基本不会对实验结果产生过大的影响,因为模型已经通过其他机制(如低秩更新)获得了足够的正则化。
3.4 lora微调模型层
对于模型不同的层进行微调的结果其实从loss曲线上观察的话区别不大,我认为应该从推理结果以及训练时长上观察并对比其效果。
当lora微调所有的线性层的时候明显最终效果会更好一点,但是训练时长相对来说就会多一些,而如果只微调其中某些层比如q、k层的话训练时间比较短,但是效果可能就会稍微差一点。
下图可以看下对比结果:
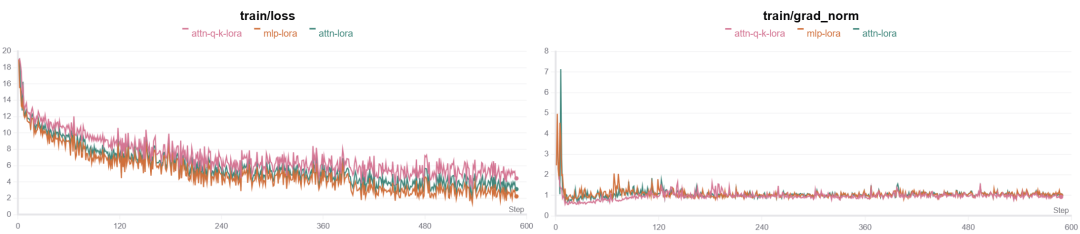

其中attn-lora是包括q、k、v、o以及前馈网络层mlp层所有层都参与lora微调,其他两个和标题表达的意思一致,分别只参与了某些层的lora微调。
从上图可以看出,其实模型收敛的情况相似,差别不大, 但是只训练两层的话训练时间上能短一些,然后对于推理结果的评估需要参考比较多的测试集,理论上其实相差不大。
3.5 训练周期epoch
当训练模型时,选择适当的训练周期(epoch)数量是至关重要的。epoch指的是整个训练数据集通过模型的次数。
过多的训练周期可能会导致模型在训练集上表现优秀,但是在其他数据集上可能表现不好,这是由于训练周期过长可能会导致模型泛化能力减弱。
因此选择合适的epoch对于微调来说至关重要,epoch在5以内的话效果不错,如果更大的epoch就可能削弱模型的泛化能力了。
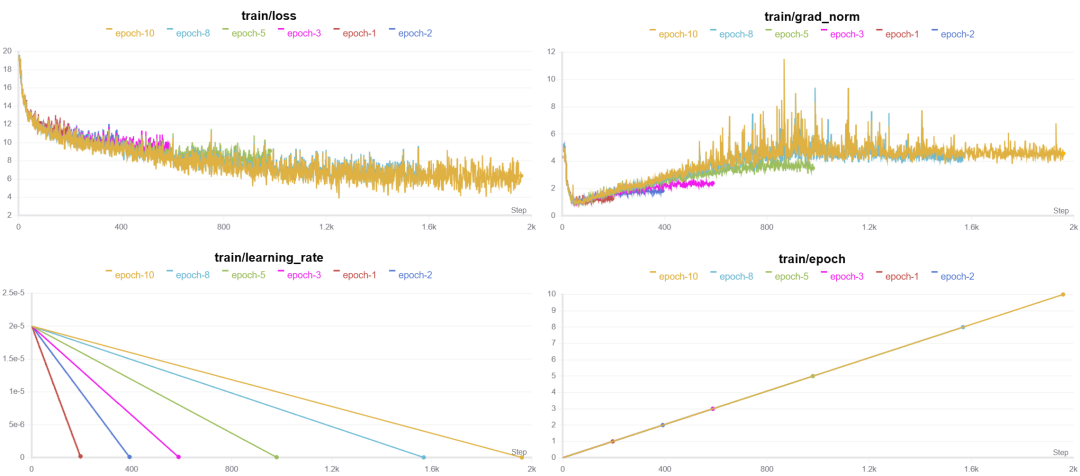
注意:
图中梯度grad_norm变化先下降后上升最后平稳的趋势是因为这些实验的学习率设置过低,导致了梯度更新太小,随后推动模型逃离局部最小值而上升。本次实验合适的学习率大概是1e-3~2e-4之间,如果想观察下epoch过多的情况可以使用较少的数据集训练,设置合适的学习率来观察结果。
3.6 批次大小batch_size
batch_size是指在模型训练的单次迭代中同时处理的样本数量。这个参数直接影响到模型训练的内存消耗和计算效率。较大的batch_size可以提高内存利用率和训练速度,但也可能导致模型训练的稳定性下降,以及需要更多的内存资源。较小的batch_size可以提高模型训练的稳定性,但可能会降低训练效率。
而我们常常在设置训练参数的时候需要设置per_device_train_batch_size,这个参数是指在每个训练设备(如GPU)上用于训练的批次大小。这个参数特别有用,当你有多个训练设备时,它允许你为每个设备单独设置批次大小。例如,如果你有4个GPU,并且设置per_device_train_batch_size为2,那么总共的batch_size将是8(2个样本每个GPU乘以4个GPU)。
这个参数可以帮助你更细致地控制每个训练设备上的内存消耗和计算负载。
我们可以先看下训练过程:
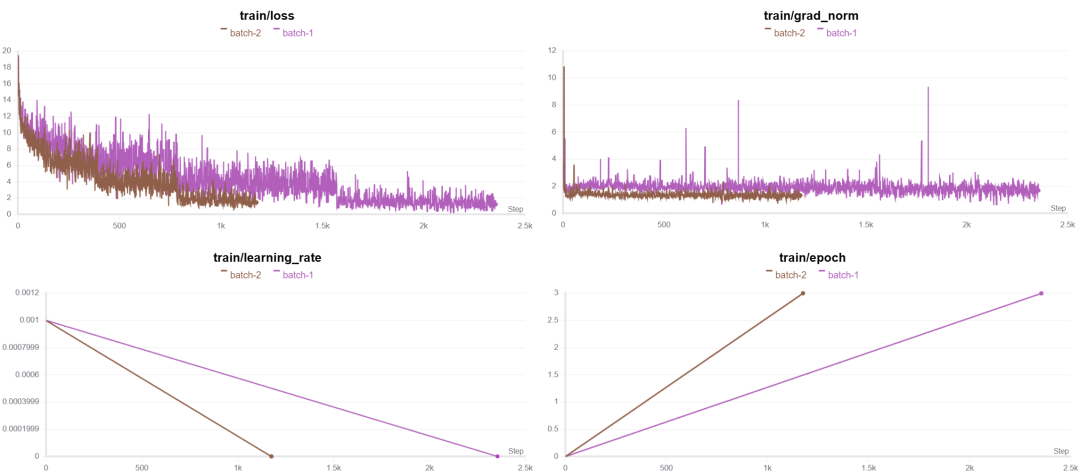
为什么per_device_train_batch_size设置的大一点,模型收敛效果显著增加?:
这里我都使用的是一块卡,然后单线程运行,因此总共的batch_size分别是1x1、1x2(num_gpus x per_device_train_batch_size),较大的batch_size使得每次更新时,模型所计算的梯度更加稳定和准确。
但是较小的batch_size每次更新的梯度可能受个别样本的影响较大,因此训练过程的噪声较多,可能导致模型在优化时偏离最优解,这可能会导致训练过程不稳定或者收敛速度较慢。我们可以从图中明显看出区别。
然后我们看下训练时长的差别:

能明显看出当设置batch较大的时候训练时长缩短,这是因为一次训练可以同时训练两条数据,理论上可以缩减一小时,因为多了一倍,这里相差了40多分钟,有可能是卡的问题,总之,可以适当选择batch来提高训练效率。
最后我们观察下GPU的使用情况:
SwanLab更新的系统监测,还有硬件条件日志,我们可以直接在官网上随时查看实验时硬件设备情况
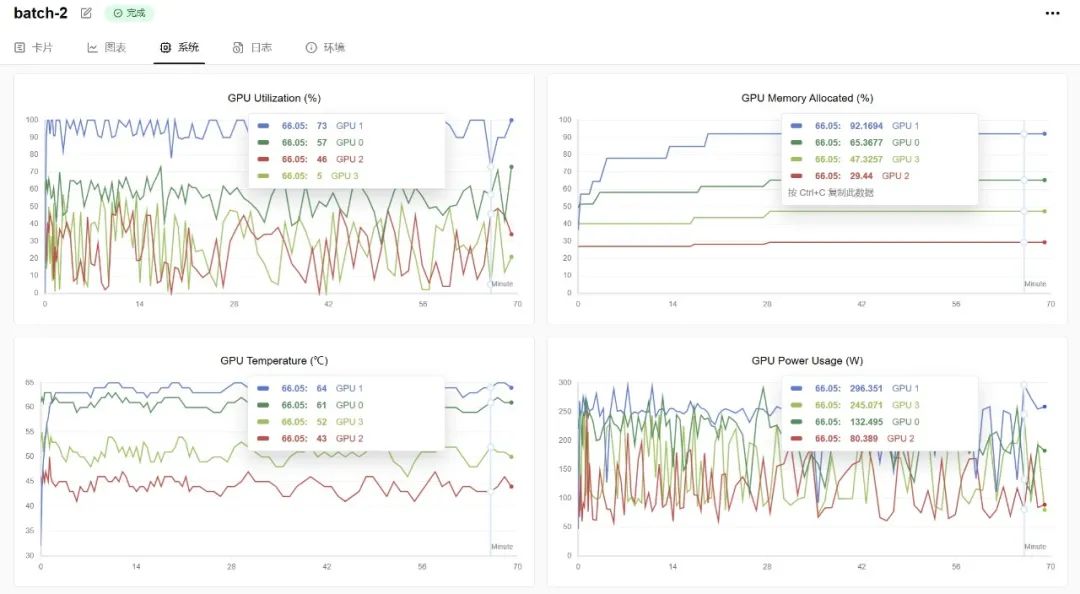
其中GPU1是batch=2的时候的情况,GPU0是batch=1的时候的硬件,可以看到从显存的使用上,batch=1的时候大概使用了26GB,batch=2的时候使用了36GB。
3.7 梯度累计步数gradient_accumulation_steps
该参数用于在微调或训练过程中控制梯度累积的步数。简单来说,它表示在进行一次权重更新之前,累积多少个批次的梯度。其在深度学习训练中的作用非常重要,尤其是在显存有限时。
gradient_accumulation_steps是指每经过一定数量的batch后才进行一次梯度更新。举例来说:
如果 batch size = 4,gradient_accumulation_steps = 2,那么实际的训练批次大小相当于 8(即 batch size * gradient_accumulation_steps)。梯度累积使得虽然每个批次大小较小,但通过累积多个批次的梯度后再进行一次反向传播和权重更新,从而有效地“模拟”了更大的批次大小。
而从上面的per_device_train_batch_size上我们也可以看出,当计算出的batch越大,对显存的消耗越多,但是在合适范围内,模型收敛效果也越好,具体我们可以观察下下面的图:
官方最新中文版的wps下载网址是什么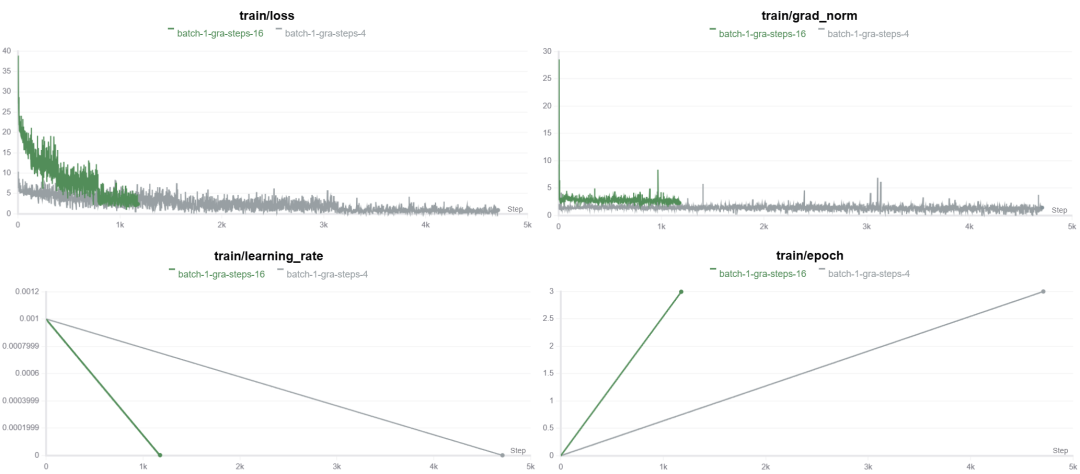
可以看到,当batch_size具体比较小的时候,总共的步长steps会比较长,而且我们设置的值是4倍的关系,steps也是4倍的关系,而当gradient_accumulation_steps设置的比较高,这里是16的时候,模型会在很小step的时候收敛,而gradient_accumulation_steps=4的时候收敛就会比较慢,具体原因如下:
1、高的 gradient_accumulation_steps 会导致每次参数更新更精确,使得每次更新的步长较小,训练过程中的噪声减少,从而帮助模型更快找到最优解。这会导致在较少的 steps 中收敛。
2、当 gradient_accumulation_steps 设置较高时,实际上是通过增加每个更新周期的“累计样本数”来增强梯度估计的准确性。这个过程可以模拟较大的 batch_size,因为每次更新所基于的数据量变大,梯度估计更稳定。更稳定的梯度会加速模型收敛,尤其是在优化时,模型的参数更新方向更为清晰,避免了小批次带来的高噪声。
3、gradient_accumulation_steps 越大,模型的权重更新就会越少,但每次更新时基于的信息量较大。更新频率减少,梯度计算更加稳定,这有助于在较少的步骤内收敛。
注意:gradient_accumulation_steps越大,对显存的需求越高,所以该如何选择需要基于自身需求。
✨✨✨至此,您已完成全部的教程✨✨✨
领取方式在文末
学习大模型课程的重要性在于它能够极大地促进个人在人工智能领域的专业发展。大模型技术,如自然语言处理和图像识别,正在推动着人工智能的新发展阶段。通过学习大模型课程,可以掌握设计和实现基于大模型的应用系统所需的基本原理和技术,从而提升自己在数据处理、分析和决策制定方面的能力。此外,大模型技术在多个行业中的应用日益增加,掌握这一技术将有助于提高就业竞争力,并为未来的创新创业提供坚实的基础wps office免费版下载网站在哪(wps office下载后怎么安装到桌面)。
①AI+教育:智能教学助手和自动评分系统使个性化教育成为可能。通过AI分析学生的学习数据,提供量身定制的学习方案,提高学习效果。
②AI+医疗:智能诊断系统和个性化医疗方案让医疗服务更加精准高效。AI可以分析医学影像,辅助医生进行早期诊断,同时根据患者数据制定个性化治疗方案。
③AI+金融:智能投顾和风险管理系统帮助投资者做出更明智的决策,并实时监控金融市场,识别潜在风险。
④AI+制造:智能制造和自动化工厂提高了生产效率和质量。通过AI技术,工厂可以实现设备预测性维护,减少停机时间。
…
这些案例表明,学习大模型课程不仅能够提升个人技能,还能为企业带来实际效益,推动行业创新发展。
如果你对大模型感兴趣,可以看看我整合并且整理成了一份AI大模型资料包,需要的小伙伴文末免费领取哦,无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

一、 AI大模型学习路线图
整个学习分为7个阶段


二、AI大 精简版的wps下载网站在哪呢模型实战案例
涵盖AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,皆可用。



三、视频和书籍PDF合集
从入门到进阶这里都有,跟着老师学习事半功倍。



四、LLM面试题


五、AI产品经理面试题

😝朋友们如果有需要的话,可以V扫描下方二维码联系领取~
中文最新版的wps下载地址
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]👈
Hi,大家好呀~我是一枚对AI十分感兴趣的一枚程序wps office免费版下载网站在哪员,一直在思考如何能够利用openAI技术,搞一搞自己的wps office免费版的下载的网站是什么小副业。去年2月,chatwps office 的官方的下载的网址怎么找(wps官网下载电脑版)gpt一夜爆火。没想到wps官网的下载的地址fwps office 官方下载的网址怎么找(wps官网下载免费版)0c;今
最新官网wps的下载网址哪里有 Small PDF合并分割软件wps office的免费版下载的地址在哪里主要运用在将PDF文档进行按wps office 的官方的下载网站是多少需求分割、合并,截取或结合成有用的文档,再进行后续的转换或者编辑等。利用Small PDF合并wps官网的下载网站在哪(wps office下载手机)分割软件可以有效对文件进行二次整合的综合解决。  
wps最新的官方下载网址哪里有wps最新的官方的下载网站ChatGPTwps电脑版下载的网址 4.0 目前是收费模式,但微软已经在Skype中集成了一个 免费的Bing聊天机器人,它可以和你进行 wps官网下载的入口在哪有趣和有用的对话,帮助你找到你想要的信息,也可以为你创造一些富有想象力和创新性
SIMA是DeepMind推出的一个wps 官网下载的地址在哪(wps下载电脑版没反应怎么办)通用AI代理,可以在广泛的游戏世界中理解并执行任务。以下是SIMA的详细介绍:wpswps 的官网的下载地方怎么找 官网下载的地址在哪(wps下载电脑版没反应怎么办)官方最新中文版wps的下载的地方哪里有SIMA是一个多 wps官网的下载的地方在哪世界AI
أفضل نماذج الذكاء wps office的免费版下载的网站怎么找 الاصطناعي في مكان واحد. قارن الإجابات بين 官网最新版的wps下载的地方是什么-R1، o3-mini، o1، GPT-4o wps office的免费版的下载入口在哪(wps官网是什么)، Claude، Gemini،wps电脑版的下载的网址的方法
Nejlepší AI wps office 官方的下载的网址怎么找 modely na jednom místěwps office 官方的下载的网址怎么找. Porovnejte odpovědi mezi wps office免费版的下载网站怎么找 官网最新版的wps下载的地方是什么-R1, o3-mini, o1, GPT-4o, wps的电脑版下载的地方在哪 Claude, wps office 的官方下载网站怎么找 Ge